

𝕊𝕚𝕤𝕪𝕡𝕙𝕖𝕒𝕟
A little insane, but in a good way.





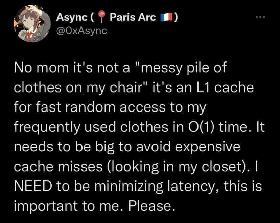
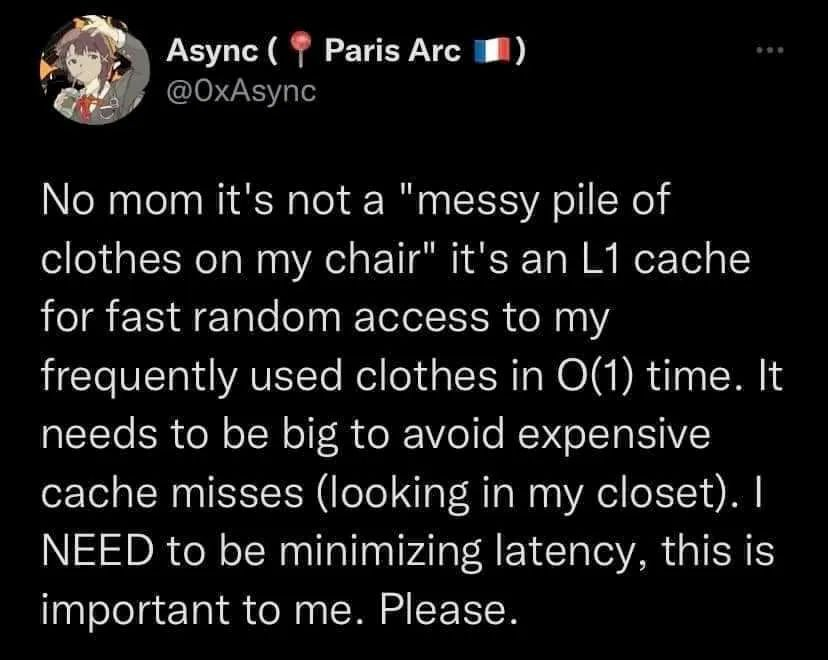
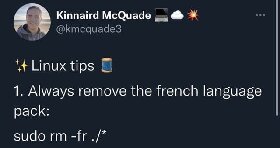
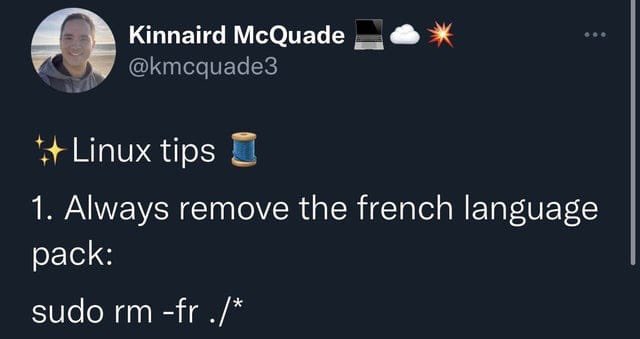
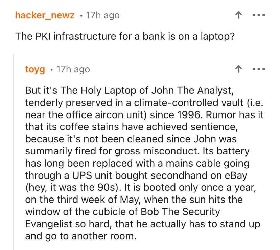
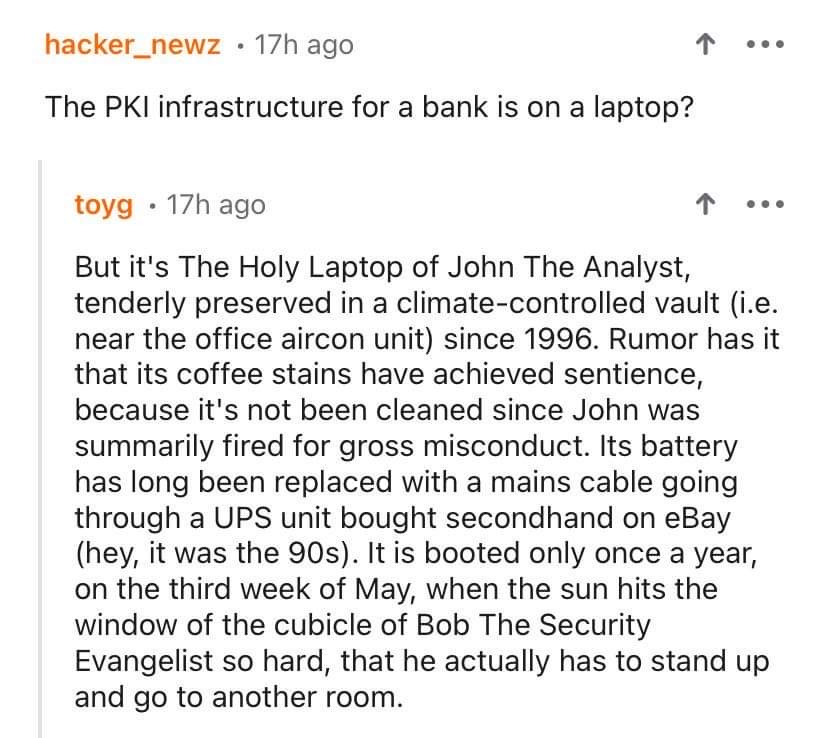
These are all very useful features! Is there any chance they will get merged into the main Lemmy codebase?








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The problem is that they “see” the text at the token level instead of the level of characters. That’s why they are bad at reversing strings or counting characters, for example. They perceive tokens as the atomic units of text instead of characters. For example, see how this comment gets tokenized:
With the token IDs shown:
The current ChatGPTs got pretty good at these tasks but they are still hard for them.
Here is an example of a (admittedly more complicated) character-level task failing:
Source: https://www.reddit.com/r/ChatGPT/comments/11z9tuk/chatgpt_vs_reversed_text/ (It’s from the devil’s website, so don’t open it)
Related tweet by @karpathy:
https://twitter.com/karpathy/status/1657949234535211009
Text reversing example from a tweet by @npew:
EDIT: sorry for the infodump, I just find these topics fascinating.
@AutoTLDR